AI产品生存指南:在巨头模型的阴影下,如何构建不可被碾压的竞争壁垒?
AI PM 竞争壁垒 产品策略
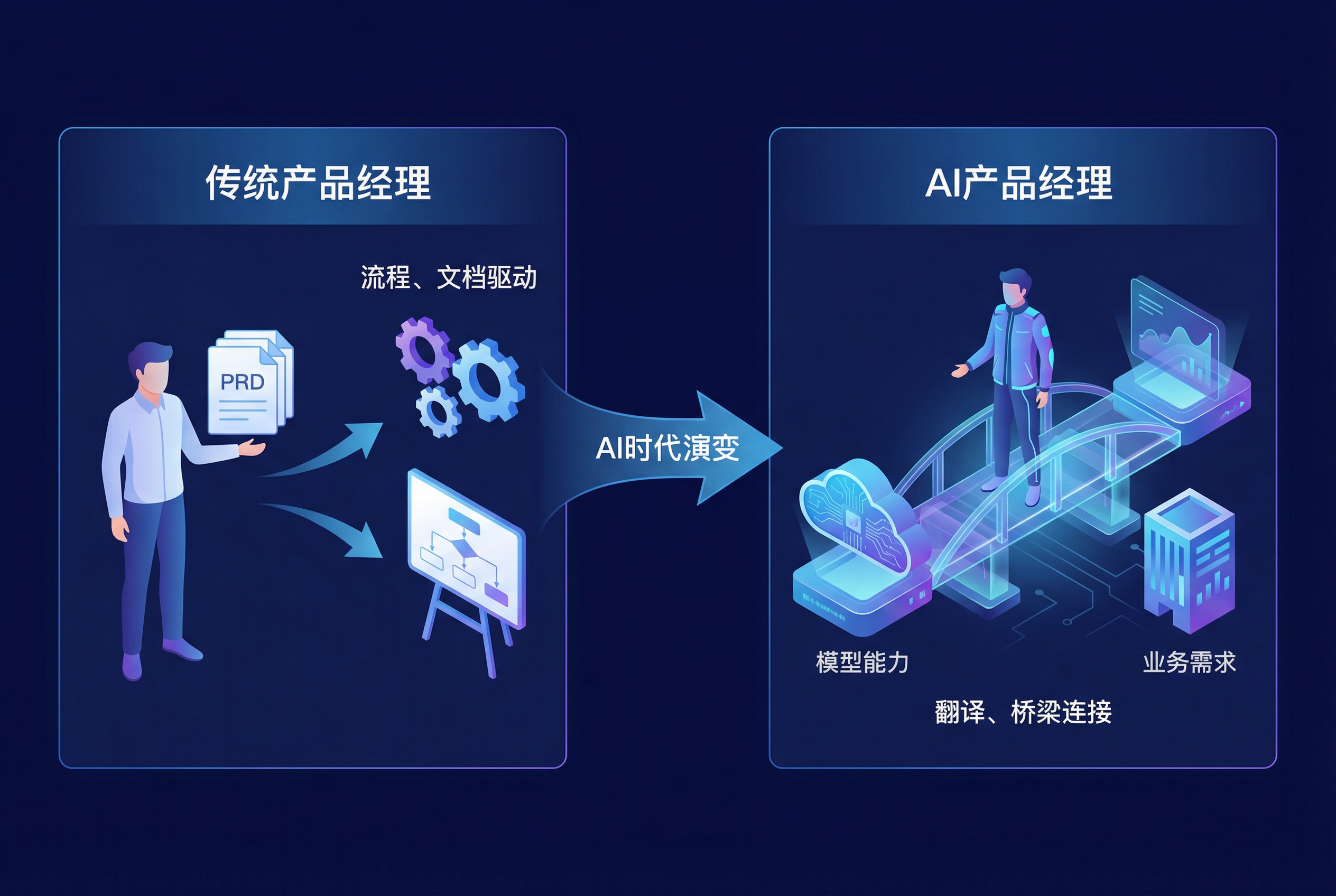
在移动互联网时代,我们习惯用 DAU(日活跃用户)或转化率来衡量成败。但在 AI 时代,规则变了。当 GPT-4o 的基础能力决定了产品的 智力上限 时,AI PM 的核心价值不再是”把功能做出来”,而是 “定义什么是正确的结果”。在这个模型能力指数级迭代的战场上,AIPM 必须掌握一套全新的生存法则:如何预判模型的边界?如何建立私有的评估体系?以及,如何在巨头模型的阴影下,构建自己的”长板”?
本文将结合我构建两个 AI 0-1 产品(小红书智能体、AIGC图片生成站)的实战经验,探讨 AI 产品经理如何构建竞争壁垒。
一、核心能力重塑:动手能力、翻译能力,模型边界认知
AI PM 处于算法研究者和最终用户之间的关键接口,我们的核心任务是 弥合”模型能力”与”业务需求”之间的巨大鸿沟。所以我们需要动手能力、“翻译能力”,以及预判模型边界的洞察力。

动手能力的”全栈化”
这里的”全栈”不是指你要写底层代码,而是指 “全流程闭环能力”。
- 实战感悟: 在我独立构建 AIGC 网站时,我必须亲自去使用大模型,换不同的prompt测试不同的大模型,调大模型的 API、等等,为什么?因为 只有亲手高频调用过大模型 API,你才能真正摸清模型的边界。
- 价值: 这种动手能力能让你建立对模型能力的”体感”。你知道哪些需求是模型”踮踮脚”就能做到的,哪些是目前的”幻觉重灾区”,从而避免在不可行路线上浪费资源。
“翻译能力”:把业务抽象为量化的评估标准 (Benchmark)
- 传统 PM: 把用户需求翻译成 PRD(功能描述)。
- AI PM: 把用户对”好结果”的模糊期望,翻译成 可量化的评估标准 (Benchmark)。 在我的”AIGC吉卜力生成器”项目中,用户说想要”更有吉卜力味”。作为 PM,我不能只把这句话传给开发,我必须将其 翻译 为具体的维度:线条是否是手绘风?色彩饱和度是否在特定区间?光影是否具备赛璐珞风格?并为此建立一套评分体系。
边界认知:预判与防御
模型厂商正在不断吞噬应用层的空间。
- 生存法则: 如果一个功能是模型”原生”就能做好的(比如简单的文本摘要),那就不要把它作为你的核心卖点,因为你迟早会被 “碾压”。
- 策略: AI PM 必须预判模型下一步会吃掉什么,然后把资源投入到模型 “暂时做不到” 或 “需要极强上下文” 的领域。
二、评估为王:建立私有的评估体系(Benchmark)
在 AI 产品中,Evaluation (评估) > Engineering (工程)。
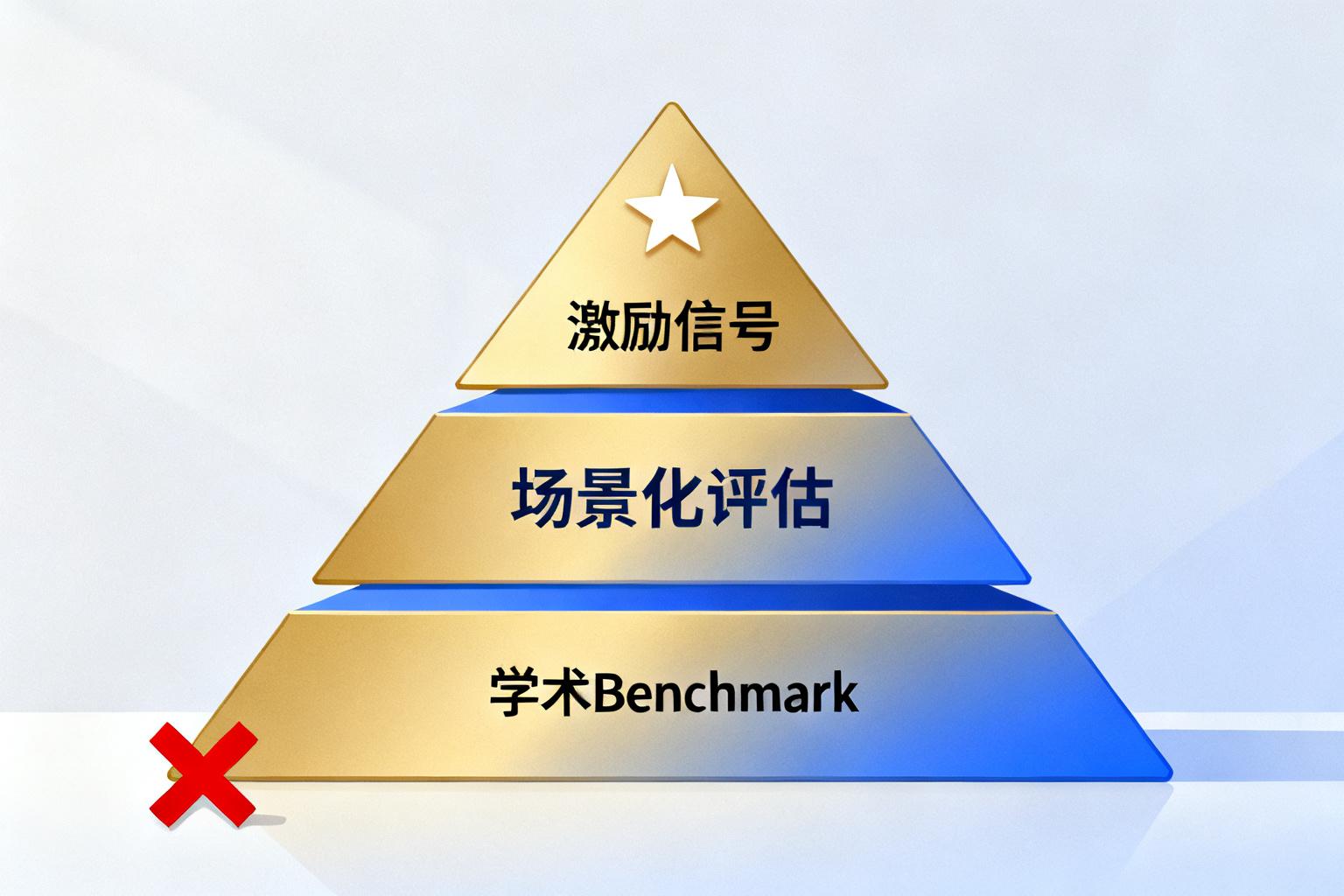
告别”学术 Benchmark”
不要迷信 MMLU 或 GSM8K 的跑分。一个在学术榜单上考满分的模型,在具体的业务场景里可能连”实习生水平”都不到。定义问题比解决问题更重要。在当前阶段,谁能定义出最符合业务场景的”好标准”,谁就拥有了指挥棒。
场景化评估:定义”好”的标准
“好”的标准是高度情境化的:
- 深度搜索场景(如 Perplexity): 核心标准是 真实性(无幻觉)、引用准确性 和 信息全面性。
- 情感陪伴场景(如 C.ai): 标准则完全反转。真实性不重要,重要的是 口语化程度、情感共鸣 和 意图理解。
- PM 的工作: 我们不仅要抽象出评估维度,还要 定义权重。比如在我的”小红书智能体”中,“网感”和”爆款结构”的权重,远高于”语法正确性”。
设计激励信号 (Reward Signal)
对于 Agent 产品,我们需要运用 强化学习 (RL) 的思维。我们要定义什么是”正反馈”。例如,当我的智能体写出一篇笔记后,如果用户选择了”一键发布”,这就是一个极强的 奖励信号;如果用户进行了大幅修改,这就是一个负反馈。PM 需要设计这种机制,让产品越用越聪明。
三、竞争壁垒:长板策略与垂直 Know-how 构建壁垒
在基础模型能力日益同质化的今天,应用层产品如果只是简单地套壳调用 API,极易被上游厂商吞噬。AI PM 必须构建独特的护城河。
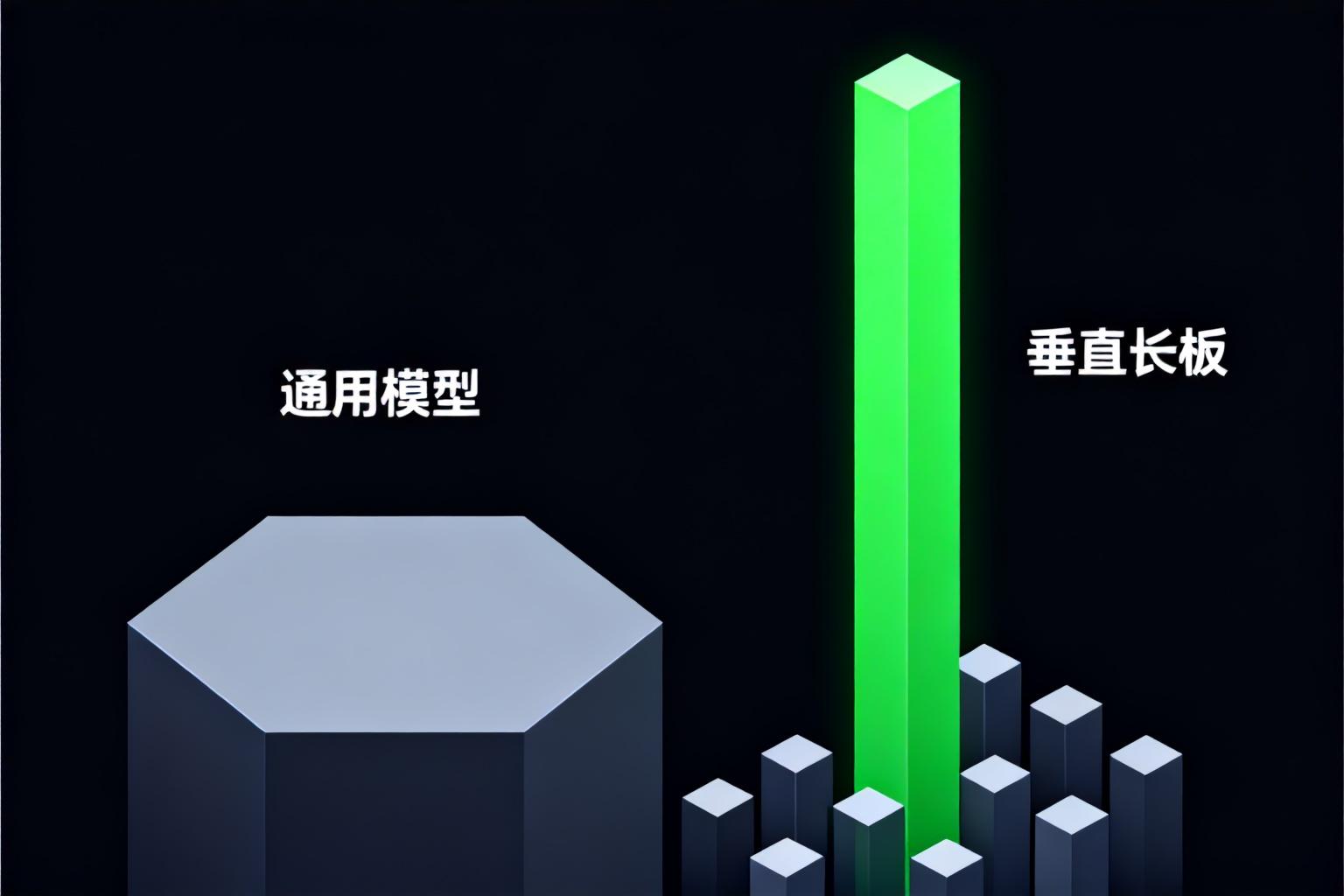
极致的长板策略:在通用模型的”平庸”中突围
大模型的本质是”求平均”。它们追求通用的准确性,往往牺牲了特定风格的极致表现。应用层产品的生存法则,不是做一个面面俱到的”六边形战士”,而是必须把某一块长板做得极长,长到用户无法忽视。
- 策略与实战: 我们需要集中资源,在一个细分场景下通过 Prompt Engineering(提示词工程) 或 Fine-tuning(微调),强行扭转大模型的”通用倾向”,确立独特的风格壁垒。
- 案例: 以我的”AIGC吉卜力网站”为例,虽然 GPT-4o 原生就能画图,但它的输出往往带有强烈的”AI 塑料感”或风格不稳定。我没有试图做一个”全能绘图工具”,而是死磕”吉卜力治愈风”这一个点。通过 Master Prompt(主控提示词) 的极致调优,我的工具在细分领域的稳定性远超通用模型。用户为了这个确定的”长板体验”,愿意付出额外的迁移成本。
垂直领域的 Know-how:将”行业潜规则”代码化
通用模型虽然博学,读取了整个互联网的数据,但它们不懂行业的”行话”、不懂”潜规则”,也不懂专家的”直觉”。真正的壁垒,在于将这些隐性的”垂直专业领域知识”显性化,并固化到产品流程中。
- 策略与实战: AI PM 需要充当”领域专家”和”算法”之间的翻译官,把那些只存在于老手脑子里的经验,拆解为 AI Agent 的 工作流(Workflow)或评估标准(Evaluation Criteria)。
- 案例: 在我的”小红书智能体”中,通用大模型只会写”正确的废话”。但我深知小红书爆款的逻辑——“情绪价值大于信息价值”、“封面点击率决胜负”。这就是我的 Know-how。我将这些经验固化在 Prompt 和 Workflow 中(例如:先让 AI 分析封面的色彩心理学,再让 AI 用”反差法”起标题)。这种基于行业深度的流程编排,是通用模型无法通过简单对话复制的”黑盒壁垒”。
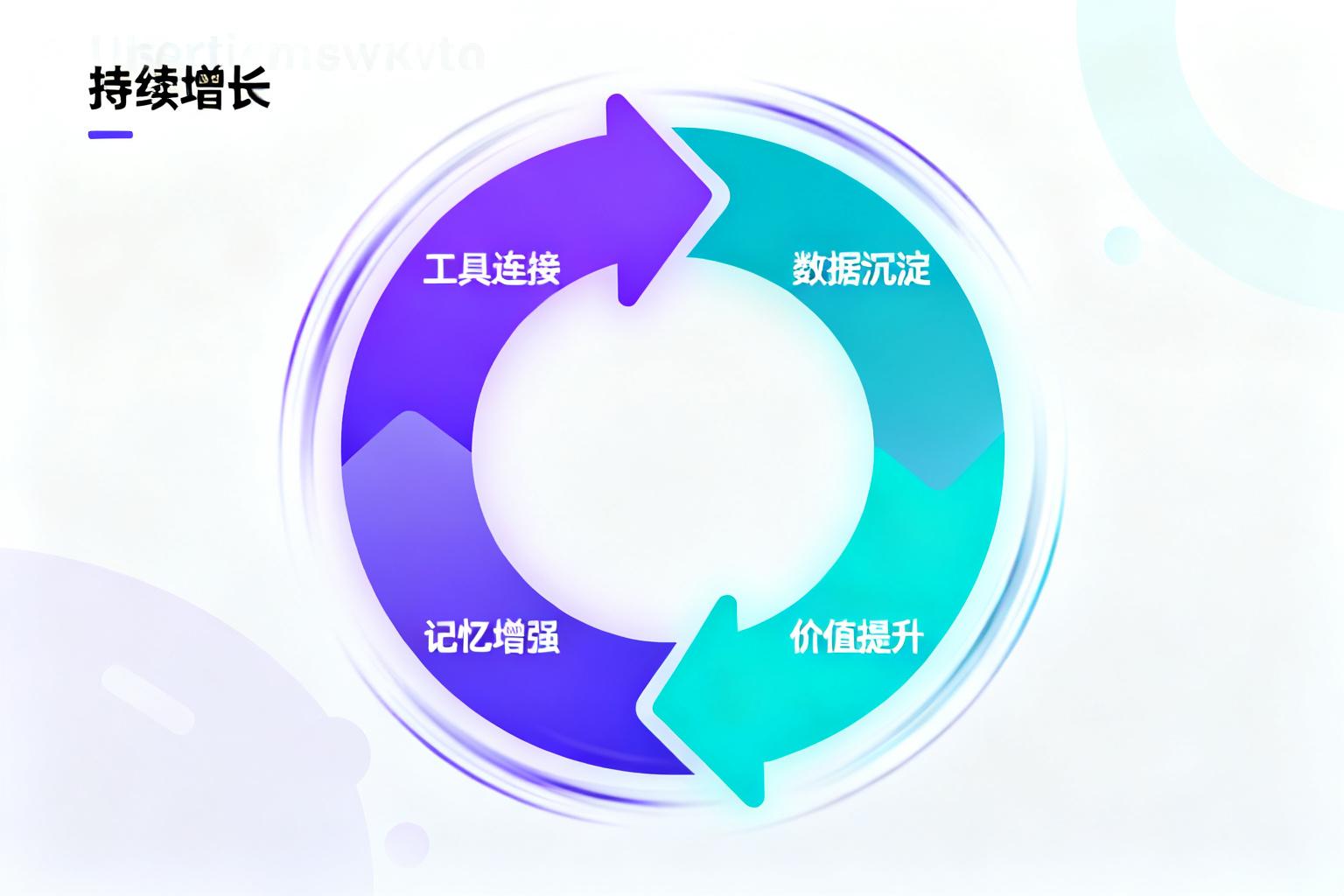
复利效应:构建”越用越懂你”的数据飞轮
软件时代,壁垒往往是功能;AI 时代,壁垒是 数据与连接。我们必须设计一套机制,让产品随着使用次数的增加,价值呈指数级增长,从而产生高昂的迁移成本。
- 工具复利(连接): Agent 接入的工具越多,工具之间的组合玩法就越呈现指数级爆炸。
- 数据复利(记忆): 这是更深的壁垒。在我的产品设计中,我引入了 “私有知识库(RAG)” 机制。用户每一次上传的素材、每一次对生成结果的修正,都会被沉淀下来。随着时间推移,Agent 不再是一个冷冰冰的工具,而是一个拥有用户 “独家记忆” 的伙伴,做到”越用越懂我”。
结语
AI 时代的 PM,本质上是一位 “构造师”。我们不需要重复造轮子(模型训练),我们需要做的是:用”全栈”的动手能力去探索边界,用”翻译官”的思维去建立评估标准,用”垂直 Know-how”去构建长板。只有这样,我们才能在模型能力不断水涨船高的洪流中,不被淹没,反而乘风破浪。