AI 产品拆解—ListenHub:把任意内容变成播客的智能音频 Agent
AI Agent 产品拆解 音频AI
ListenHub 是面向”把任意内容转成可听音频”的播客工具,核心场景是用超写实中文语音在多终端上高效消费和创作内容。
产品定位与使用场景
-
核心定位: 一站式 “AI 播客 + 解说音频 + 智能 TTS” 工具,强调”首个书面语转口语的智能 TTS”和”超真实人声”。
-
主要使用场景:
- 将文章、网页 URL、PDF/TXT 等文档一键转为播客或解说音频,用于信息获取和内容再创作。
- 创作者用它批量产出播客、有声解说、培训音频、短视频配音等,作为”AI 嘴替”。
- To B/团队:为公司产品、销售培训、知识库等快速生成标准化音频物料。

智能体/Agent 技术架构拆解(推测性分析)
从产品形态看,更接近”内容型 Agent”,在感知、规划、工具调用、交互上大致是:
感知层
- 接收多源文本输入:纯文本、URL 抓取网页正文、上传 PDF/TXT 等,并做清洗与结构化(分段、标题、要点抽取)。
- 对长文内容进行语义理解,识别主题、语气、角色(单人/双人对话)等。此处通常会用大模型 + RAG 或自研内容分析模块。
规划层
- 基于 LLM 的脚本规划: 将原始内容”播客化”,包括信息筛选、结构重组、加入过渡语、口语化改写等,FlowSpeech 明确强调”书面语转口语”,说明不只是纯 TTS,而是有一层文案重写/规划 Agent。
- 对话/多轮创作: 用户通过自然对话调整脚本(口吻、时长、观点密度),系统需要在对话状态下持续维护”当前节目脚本”的工作记忆。主页”自然对话,获取你需要的任何信息”指向这一点。
工具调用层
- 核心工具 1:TTS/FlowSpeech 引擎,负责超真实人声合成、口语化节奏控制、情绪/语气设计,并支持流式输出(几秒内开始播放,千字约 10 秒生成)。
- 核心工具 2:多角色语音库 + 声音克隆(专业版 2 个、商业版 5 个),通过语音克隆模型定制”个人 AI 声音”。
- 周边工具:
- Nano Banana Pro 生成封面图片(图生图/文生图),集成于创作流程。
- 音视频导出(生成 MP3/MP4 及带字幕的解说视频)。
- 即将/已有的 API & MCP,对外以服务形式暴露 TTS 与播客生成管线,支持开发者工具调用与插件化集成。
交互与反馈层
- 用户侧: 网页端 + iOS + 即将上线的 Android + 浏览器插件,统一使用”创作/探索/资料库”结构,让用户可以一键创作、浏览他人作品、管理自己的节目库。
- 反馈与迭代: 通过播放数据、订阅/点赞、内容消费行为,反向优化推荐与创作模版;从访谈看,团队非常关注”第一次自己生成并听完”的 Aha Moment,用这一节点驱动付费转化。
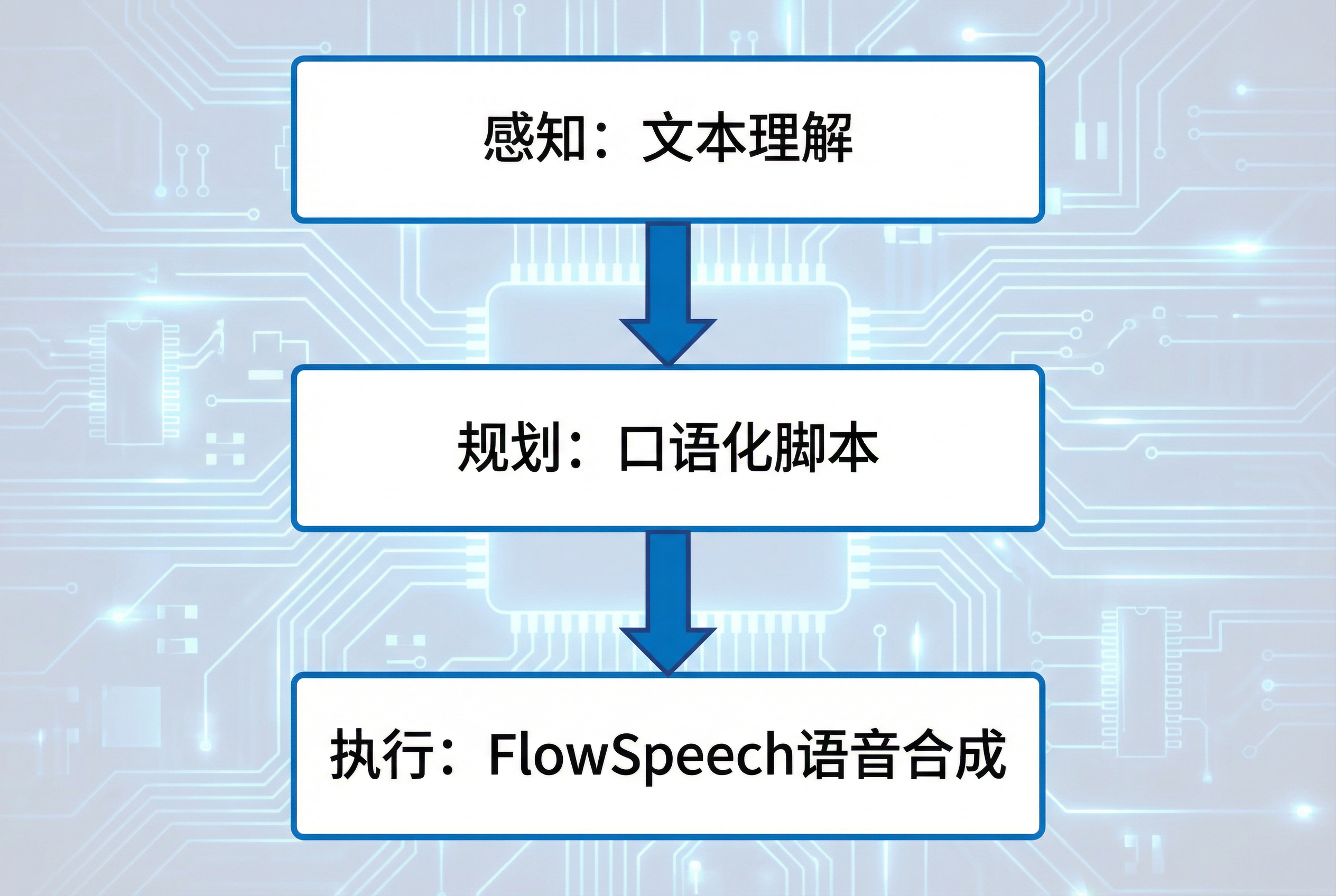
整体来看,ListenHub 当前的 Agent 更偏”有清晰 workflow 的半自主内容 Agent”,在规划和工具编排上做了针对音频场景的深度垂直优化,而非通用多工具 Task Agent。
商业化路径与壁垒
商业化模式
- 订阅制为主: 按年付费节省 20%,分创作者($9/月)、专业版($19/月)、商业版($39/月)三个档位,对应不同积分配额、克隆声次数和 API/MCP 权限等。
- 使用计量: 积分机制约束音频生成次数/时长,与高算力 TTS 成本对齐;免费用户有月度免费额度,用于拉新与体验。
- To B 机会: 商业版定位团队/小企业,提供多克隆声、无品牌、API 能力,可向品牌内容、教育培训、音频 MCN 等场景延展。
商业壁垒(现状与潜力)
技术壁垒:
- FlowSpeech 打的 USP 是”书面语→口语的智能 TTS + 超真实人声 + 流式低延迟”,在中文细腻语气和长文本自然度上可能具有领先优势,对标的是通用大厂 TTS 难以针对内容场景深调优的问题。
- 私有语料与语音克隆能力,沉淀了创作者音色、口头禅、节奏偏好,形成难迁移的”个性化资产”。
产品&体验壁垒:
- 一体化”从内容到节目”的链路(抓取-改写-脚本-配音-封面-导出)比单点 TTS 工具在效率和心智层都更强,能抢占用户”做音频就打开 ListenHub”的入口位置。
- 多平台覆盖(Web / iOS / Android / 插件)与探索页内容生态,增强留存与品牌曝光。
生态与数据壁垒(在构建中):
- 若能通过 API 与 MCP 进入其他 Agent/工具生态(如知识库、创作工具、教育平台),ListenHub 会成为”音频输出层基础设施”,在 B 端形成粘性。
- 越多创作者和听众积累,平台会掌握更丰富的”什么样的脚本和语气更好听”的数据,持续迭代模型。

面临的主要挑战
市场与竞争
- AI TTS、播客生成领域竞争者众多,包括大厂通用 TTS(Azure、Google、阿里等),独立音频工具(如 Podcastle、Descript 类)以及国内外新兴 AI 音频产品,差异化压力很大。
- 小红书、B 站、抖音生态里已经存在大量基于通用 TTS 的内容,ListenHub 需要证明”口语化 + 超真实 + 工作流”能明显拉开体验和效率差距。
技术与成本
- 超真实人声 + 流式输出意味着推理成本不低,随着用户数和时长增长,云算力开销与 API 价格之间的平衡是关键问题。
- 声音克隆涉及隐私与合规,需在防止滥用(未经授权克隆声音)与开放自定义能力之间找到平衡。
增长与留存
- 如何让用户从”尝鲜生成几条”进化到”日常内容消费/创作都靠 ListenHub”,需要在推荐系统、订阅机制和协同创作(与团队/社群)上持续打磨。
- To B 变现需要更强的行业解决方案包装,而目前产品在官网上呈现仍偏通用创作者工具,对垂类场景(教育、企业培训、内容营销)故事讲得不够具体。
如果我是产品经理,下一步会做什么(个人思考)
结合最近对 Agent 架构和商业化的研究,可以优先从”把 ListenHub 从工具进化为智能音频 Agent 平台”入手:
1. 在”感知-规划”层增强智能能力
- 上线”智能播客大纲/脚本 Agent”:支持用户只输入主题或一段对话,让 Agent 主动去网络检索资料、自动构建大纲、生成多期内容规划,而不仅是对既有文本做播客化。
- 增加”风格模版 + 一键调参”(信息密度、情绪、角色设定),把复杂 prompt 固化为可视化选项,降低普通创作者门槛。
2. 打造 Agent 化工作流与插件生态
- 基于 MCP/API 暴露”脚本规划 + FlowSpeech + 导出”的全链路,让其他 Agent(如知识管理、学习助理、企业内助手)可以一键调用 ListenHub 做音频输出。
- 设计”音频工作流商店”,支持用户/开发者上传工作流模版(例如:科研论文 → 通俗播客、公司周报 → 团队语音简报、品牌新品发布 → 解说视频脚本),ListenHub 官方审核与推荐。
3. 深化商业化与壁垒
- 针对企业和教育场景推出”团队空间”,提供成员管理、统一配额、品牌化音色与开屏,会比单个商业版订阅更好卖。
- 用”私有语音资产 + 数据安全”做卖点,提供企业私有部署/虚拟私有云版本,解决内容安全和合规顾虑。
4. 内容生态与分发
- 强化”探索/资料库”与外部分发整合(小宇宙、小红书、B 站、播客平台),提供一键分发和数据回流,让创作者能看到 ListenHub 带来的新增播放和收入。
- 做”听的个性化推荐”,用收听行为和互动数据驱动模型,对标”个人音频助手”的长期定位。

结语
综合来看,ListenHub 已经在”内容→脚本→TTS→播客/解说视频”的垂直链路上形成了较强的产品完整度和体验优势,但在 Agent 智能程度、生态连接和 To B 方案上仍有较大升级空间。
如果顺利把 FlowSpeech 做成”任何 Agent 和应用的默认音频输出层”,同时围绕创作者和企业搭建可复用的工作流与生态,ListenHub 有机会从一个 AI 播客工具,成长为智能音频基础设施型产品。